CJK fonts
Introduction
You may wonder, based on my previous post, how Unicode handles when the same Han character gets written differently in different languages. Writing evolves over time, so can we represent the same Han character with the same Unicode code point across languages? Unicode answers:
Even where there are substantial variations in the standard way of writing a character from locale to locale, if the fundamental identity of the character is not in question, then a single character is encoded in Unicode. … It is well-recognized that the Han characters involved are the same, even when used in different countries to write different languages. … There are occasional instances of unified characters whose typical Chinese glyph and typical Japanese glyph are distinct enough that the Chinese glyph will be unfamiliar to the typical Japanese reader, e.g., 直 U+76F4. … Where a distinction in style needs to be made (for example, Chinese-style vs. Japanese-style glyphs in the same document), appropriate fonts should be applied to the specific text as needed.
Unicode points to fonts for the responsibility of rendering characters appropriately, declaring:
The Unicode Standard is designed to encode characters, not glyphs.
So let's talk about fonts!
Fonts
Fonts exhibit surprising complexity. From the perspective of the computer, a font contains glyphs (the things you see) and rules.1 By applying the rules to the glyphs, you get text that follows the conventions of the writing system and that you can read.
Substitution
First, the computer uses some encoding standard, e.g. Unicode, to map from binary data to characters. Next, the computer applies substitution rules. As described here:
Many language systems require glyph substitutes. For example, in the Arabic script, the glyph shape that depicts a particular character varies according to its position in a word or text string. Isolated, initial, medial, and final forms of the Arabic character HAH:
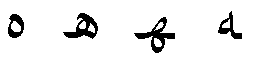
Substitution rules allow us to map multiple characters to a single glyph, single characters to multiple glyphs, and characters to different glyphs depending on the characters around them.
Positioning
After substitution, we now know the glyphs. However, the final position of these glyphs also matter. As described here:
Complex glyph positioning becomes an issue in writing systems, such as Vietnamese, that use diacritical and other marks to modify the sound or meaning of characters. These writing systems require controlled placement of all marks in relation to one another for legibility and linguistic accuracy. Vietnamese words with marks:
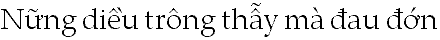
Other writing systems require sophisticated glyph positioning for correct typographic composition. For instance, Urdu glyphs are calligraphic and connect to one another along a descending, diagonal text line that proceeds from right to left.
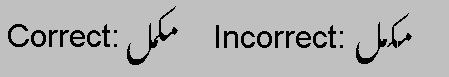
Only after applying substitution and positioning rules do we get a satisfactory rendering of text.
CJK fonts
Because they share Han characters, the same font often covers Chinese, Japanese, and Korean (CJK) text. I previously imagined you could sort of mash a bunch of strokes together to make a CJK font. However, font makers take a lot of pride and effort to make their fonts correct and beautiful. This applies especially to CJK fonts. For example, Noto Sans, which covers Latin, Cyrillic and Greek scripts, takes up only 1.3M, while Noto Sans Simplified Chinese takes up 48M!
Conclusion
Hopefully now that you've taken a peek into fonts, you appreciate the complex artistry that goes into your fonts.
I will use the OpenType font specification here. ↩︎